Høynivå maskinlæring i AWS
Amazon Web Services er så mye mer enn bare fillagring, server- og databasehosting. Vi tar for oss hva det kan tilby innen maskinlæring, samt gi en smakebit på noen av de relevante tjenestene.
Harald Vinje

Det er ingen hemmelighet at vi i Capra er glade i Amazon Web Service (AWS), og det brede spekteret av tjenester AWS har å tilby for å gjøre hverdagen til oss utviklere lettere, billigere, og mer fleksibel. Når IT-konsulenter flest hører AWS, tenker nok mange først og fremst på tjenester som fillagring, server- og databasehosting, serverless lambdafunksjoner, og kanskje containter services. Men visste du at AWS også har et rikt sett med tjenester for oss maskinlæringsinteresserte? Noen av disse tjenestene skal vi se mer på i dag!
En rekke maskinlæringstjenester i AWS
Er du tallknuseren som elsker å dypdykke i de forskjellige lagene og aktiveringsfunskjonene i nevrale nettverk? Ikke det? Kanskje du er hardwarespesialisten som vil sjekke ut hvor raskt du kan trene en modell på NVIDIAs kraftigste GPUer? Eller er du en enkel Webutvikler som vil teste ut og integrere ferdige maskinlæringsløsninger i Webappen din? Du finner uansett det du vil ha i ML-stacken til AWS!

Maskinlæringstjenestene i AWS kan deles inn i tre nivåer, som visualisert på bildet over. På det laveste nivået finner du hardwaren du kan spinne opp og leke deg med, i tillegg til kjente og kjære maskinlæringsrammeverk som TensorFlow, mxnet og PyTorch, ofte preinstallert på maskinene. På nivå to finner du det som kanskje er AWS’ mest kjente maskinlæringstjeneste, SageMaker. Dette er en serverless (hvis du vil ihvertfall) tjeneste hvor du enkelt kan sette opp og dele Notebooks, hente inn, visualisere og aggregere data, teste ut algoritmer og modeller, og deploye modellen når du er fornøyd.
På det øverste nivået finner vi maskineringstjenester som fungerer “out of the box”. Disse tjenestene er for deg som vil ta i bruk maskinlæringsalgoritmene AWS har jobbet hardt med å finpusse, uten å trenge å vite hvordan de fungerer bak kulissene. Det lar seg ofte gjøre med bare noen enkle API-kall. Å gå gjennom alle disse blir for omfattende for dette blogginnlegget, men vi skal se litt mer på mine favoritter. Vi skal også gå gjennom et lite kodeeksempel.
Amazon Rekogntition
Rekognition er AWS’ maskinlæringsbaserte bilde- og videoanalysetjeneste. Med features som label detection, text detection, content moderation, facial attribute analysis, celebrity detection og mye mer har du stort sett det du trenger for å analysere og klassifisere bildene eller videoene dine. Analysen er som regel bare et API-kall unna.
response = client.detect_labels(Image={'S3Object':{'Bucket':bucket,'Name':photo}, MaxLabels=10)
Det er bare fantasien som setter grenser for bruksområder for Rekognition. Noen eksempler inkluderer:
- verifisere at brukeren laster opp dokumenter som inneholder tekst
- sortere bilder på innhold
- moderere opplastning av bilder
- plassere et overvåkningskamera i nærheten for å spotte kjendiser du er fan av, og automatisk send e-post når du treffer (kanskje ikke heelt gdpr...)
AWS Comprehend
Er du mer interessert i å analysere tekster, er AWS Comprehend-tjenesten for deg. I Comprehend sender du inn tekst og får tilbake informasjon om teksten på et mye mer kompakt format. Comprehend kan identifisere entiteter (som f. eks navn, adresser, firmaer), nøkkelord, tema, tekstens sentiment (positivt eller negativt ladet tekst) og mer. Det kreves lite av forståelse av hvordan Comprehend funker bak kulissene for å ta det i bruk. Også her er det kun et API-kall med tilhørende tekst som skal til for å få tilbake nyttig informasjon.
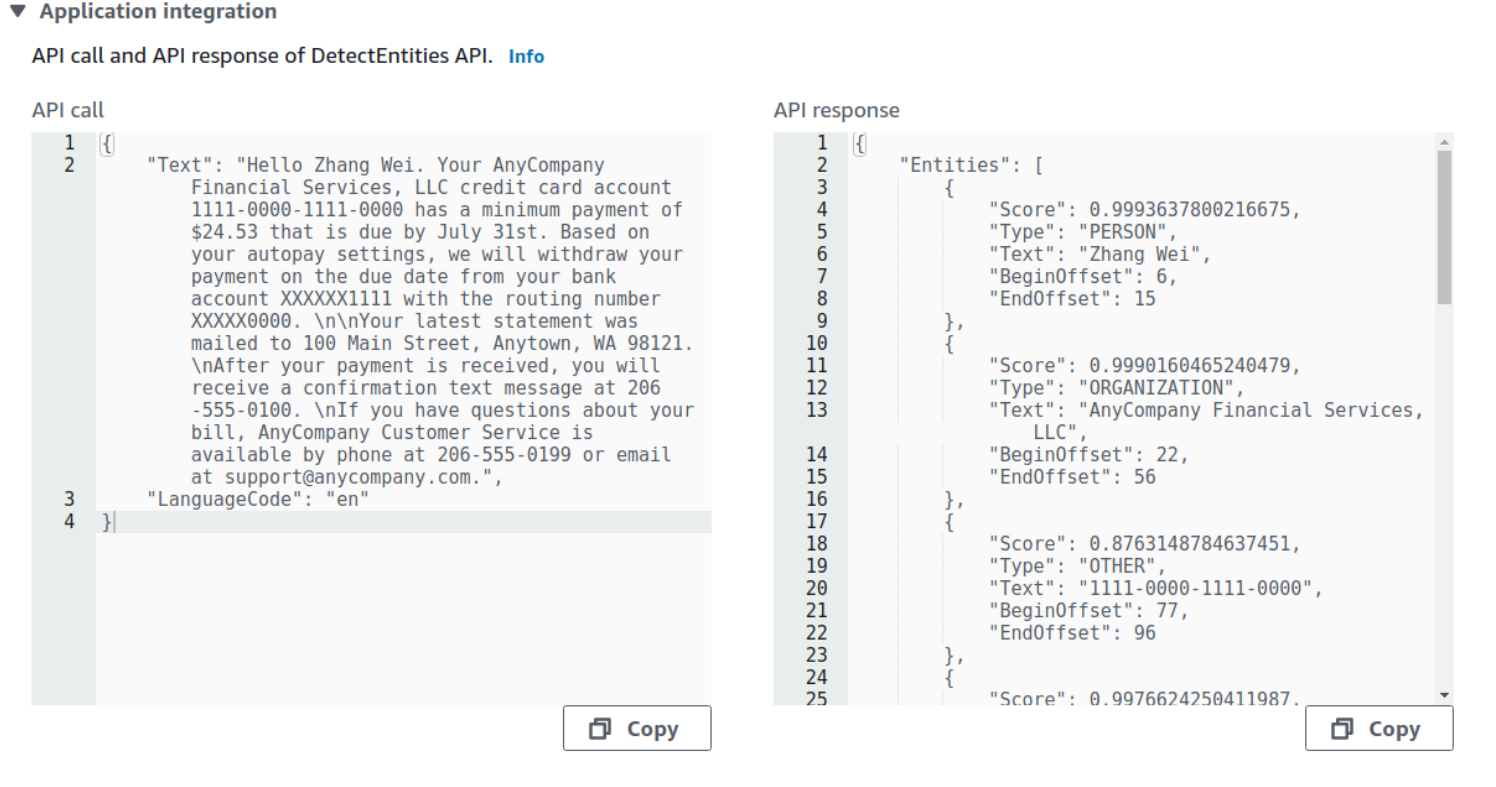
Her er det også rom for mye automatisering. Et eksempel på et use case: La oss si du har et produkt hvor kundene gir tilbakemeldinger via et skjema i nettbutikken din. Du ønsker å klassifisere tilbakemeldinger som enten positive eller negative, og lagre tilbakemeldingene i forskjellige mapper deretter. Et enkelt løsningsforslag er:
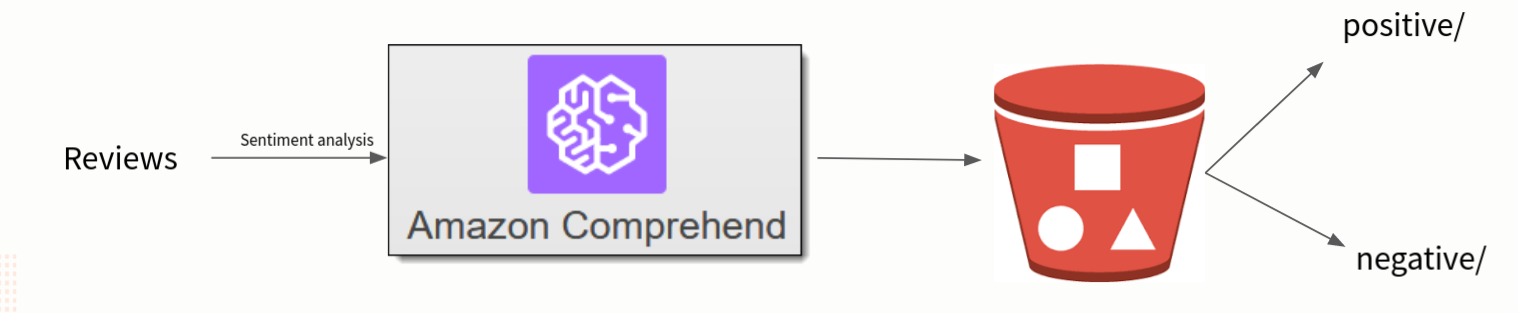
Comprehend kan som nevnt utføre sentimentanalyse, hvor du får klassifisert tekst som positivt eller negativt ladet, i tillegg til tilliten (confidence) knyttet til klassifiseringen. Disse kan plasseres i forskjellige mapper i en S3-bøtte basert på klassifiseringen, eller sendes andre steder for videre prosessering eller lagring. For å orkestrere dette kan du bruke AWS Lambda.
Andre maskinlæringstjenester i AWS
Rekognition og Comprehend er, etter min mening, de to mest nyttige ML-tjenestene som kan regnes som høynivå, men det er selvfølgelig mange andre slike tjenester AWS tilbyr, som vi skal nå gå kjapt gjennom.
Amazon Lex er AWS’ chatbot service. Du lager og deployer din egen chatbot etter skreddersydde behov. Du kan enkelt konfigurere oppførselen til chatboten din i AWS-konsollen ved bruk av såkalte “intents”, hvor du må spesifisere hvilke oppgaver du vil at chatboten skal hjelpe brukeren med. Lex kan bruke avansert Natural Language Processing (NLP) for å tolke “Intents”. Du kan også programmere direkte hvilke ord eller fraser fra brukeren chatboten skal reagere på.
For tjenester knyttet til tale (speech) har vi Amazon Transcribe (speech to text) og Amazon Polly (text to speech). Kombinerer du disse tre tjenestene kan du lage din egen Alexa-lignende enhet på følgende måte: Transcribe -> Lex -> Polly. Transcribe konverterer tale til tekst, Lex tolker teksten og returnerer tekstsvar, og Polly taler teksten fra Lex tilbake til deg!
Den siste tjenesten jeg vil nevne før vi går til kodeeksempelet er Amazon Forecast. Forecast predikerer data for fremtiden basert på historiske data som brukeren mater inn i modellen. Prediksjonene kan visualiseres i flotte grafer, eksporteres til csv-filer eller hentes via APIer. En sentral forskjell mellom Forecast og de andre nevnte tjenestene, er at for å få nyttige prediksjoner fra forecast burde du ha god domenekunnskap om tidsseriene du ønsker å predikere. Det hjelper også å ha en god forståelse om forskjellige modellene du kan bruke for å få best mulig prediksjoner.
Rekognition til bildemoderering i Web appen din
Nå skal vi se på hvordan du kan integrere AWS Rekognition i en web app i praksis. Hensikten med Web Appen er å kunne laste opp bilder, gitt at bildene blir godkjent av en modereringsfunksjon vi skal implementere. Appen er i utgangspunktet agnostisk til hvor bildet lastes opp, men i vårt tilfelle lastes det opp til S3. Under ser du kildekoden til appen, skrevet i ReactJS.
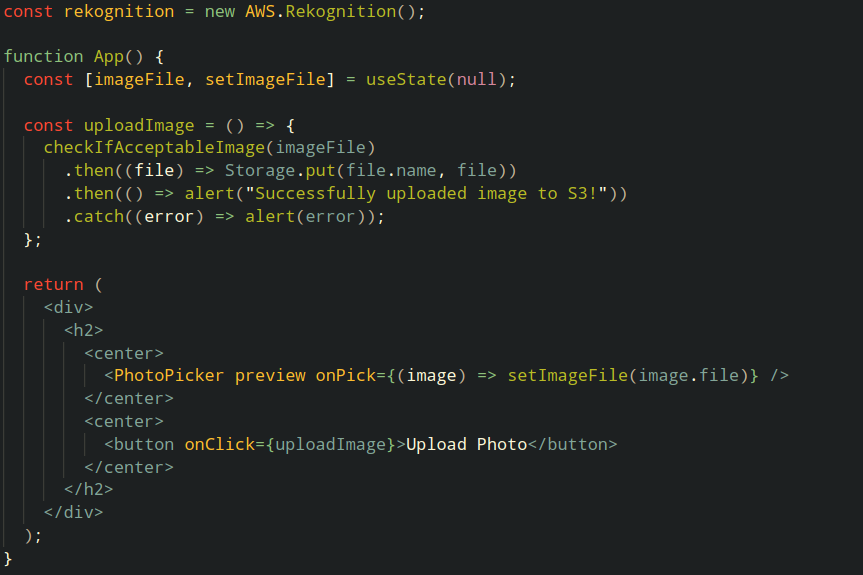
Det er i funksjonen checkIfAcceptableImage(imageFile) at Rekognition kommer inn i bildet. Den funksjonen skal vi ta en nærmere titt på nå.
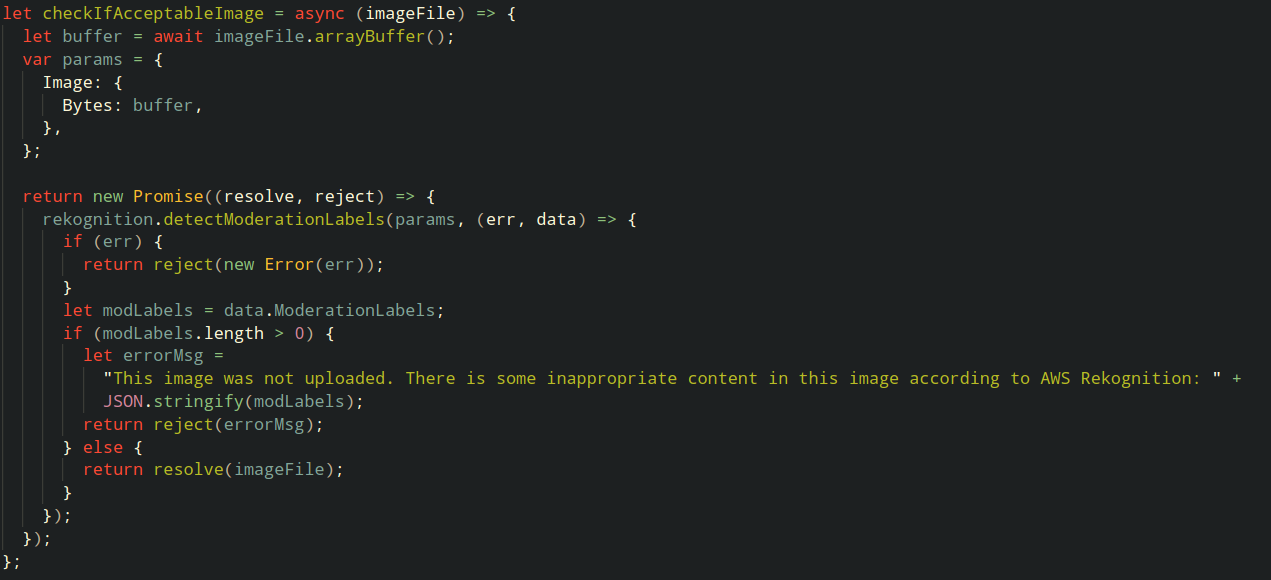
Ettersom Rekognitions SDK sender API-kall over nettet returnerer funksjonen et promise-objekt. Kallet til detectModerationLabels er stedet all magien skjer! Vi slenger inn parameterne, som inneholder bildet og en callback-funksjon. Det er i callback-funksjonen vi definerer hva vi syns er passende bilder basert på moderationLabels i responsen fra Rekognition. For å gjøre det enkelt denne gangen, så sier vi at bildet kun er akseptabelt om det ikke inneholder noen moderationLabels. Nå har vi alt vi trenger for en fungerende Web App, så la oss se på resultatet:
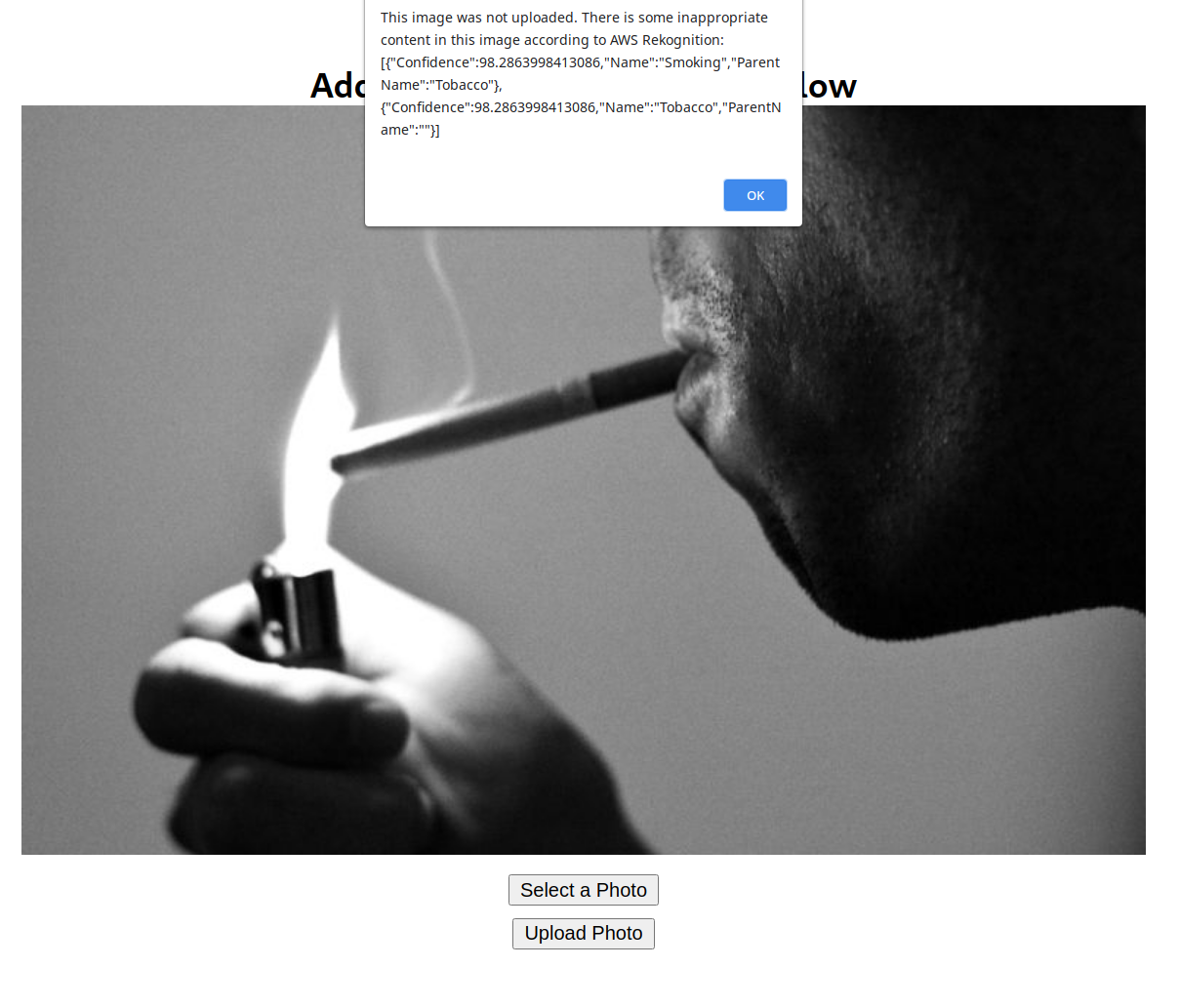
Voilà! Som vi ser så får vi en respons med labels og tilhørende confidence-score. I dette eksempelet sjekket vi om listen med labels er lenger enn 0 (altså at det er noen moderation labels på bildet), men her kan du lage egne regler med tilpassede labels etter appens behov. Si du f. eks kun vil hindre opplastning om confidence-scoren er over 90%, og la resten av modereringen gjøres av mennesker, kan du enkelt implementere dette.
Konklusjon
Vi har så vidt skrapt overflaten av maskinlæring i AWS, men jeg håper allikevel du har fått en liten smakebit og blitt nysgjerrig på hva tjenestene AWS har å tilby innen maskinlæring. Maskinlæring og sky er to teknologier i rask utvikling, så det er alfa omega å være oppdatert på hvordan det kan benyttes i praksis.